
Table of Contents
- 1 Text Classification using Machine Learning
Text Classification using Machine Learning
In this text classification using machine learning-based tutorial, we will learn about machine learning introduction, introduction to text classification, and different approaches used for text classification in machine learning.
Human knows based on experience of doing a particular task or action. So he/she do not face so much problem But how machines do all these things comes under knowledge representation and reasoning.
Questions and Answers
By the end of this machine learning algorithm for text classification-based tutorial, computer science graduates will answer the following questions and machine learning concepts.
- What is machine learning?
- What is artificial intelligence?
- What do you mean by text classification?
- What are different ways of text classification?
- Various machine learning algorithms for text classification.
- The basic machine learning model for text classification.
- What is deep learning?
- What is a word bag or word bag?
- What is regression?
What is Machine Learning?
Machine Learning is a sub-discipline in the field of Artificial Intelligence (AI) capable of creating algorithms that allow computers to learn to perform tasks from data instead of being explicitly programmed.
These “models” can identify patterns from training data (examples) and can forecast future events with a certain level of confidence and make decisions without human intervention. This is especially valuable for processing large databases and automating processes.
What is Artificial Intelligence?
Artificial Intelligence (AI) is the capability of a machine to intimate intelligent human behaviour. AI’s bottlenecks are handled by Machine Learning (ML), and bottlenecks of machine learning are handled by Deep learning.
Text Classification
Text classification is a process in which we assign an assign a set of predefined class or category. The text classification process is also known as text tagging or text categorization. Text classifier is used to organize, structure and organize the text.
Text sorting can be thought of as a supervised learning problem where you have a set where it is a text and is the class associated with that text example, consider a text “have a great day” the class associated with this text is “positive”.
This problem can be modelled using the Bernoulli distribution algorithms, assuming that each word is found or not in the document or statement.
| Text | Class |
| excellent day | positive |
| good afternoon | positive |
| I hate Monday | negative |
| cows depress me | Negative |
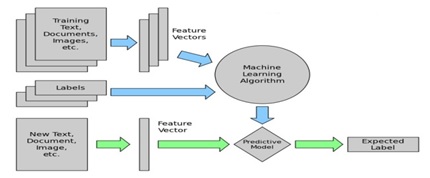
Basic Text Classification Model
Text classification model some time also known as text classifier which takes text as an input then analyzes it and automatically assign a tag. Basic text classification model is as shown in following figure.

Different ways of Text Classification
Text classification can be done in two ways
- Manual classification
- Automatic classification
In a manual classification of text, human analyze the text and assign the class it accordingly. This method provides a better quality of the result, but this is more time consuming and expensive.
In automatically text classification method, natural language processing or machine learning is used to classify the text. There are various models of text classification in automatic text classification, which are as follows
- Rule-Based Model
- Machine Learning-Based System
- Hybrid System
Here in this tutorial, we are mainly focusing on a machine learning-based text classification model.
Basic Machine Learning Based Text Classification
Machine learning-based text classification model or algorithms works on the basis of past observations in order to classify the text. Pre-labelled examples are used as training data. The machine learning algorithm can learn the different associations between text pieces and the particular output or tag to be expected for a particular input. This model is based on a supervised machine learning algorithm.
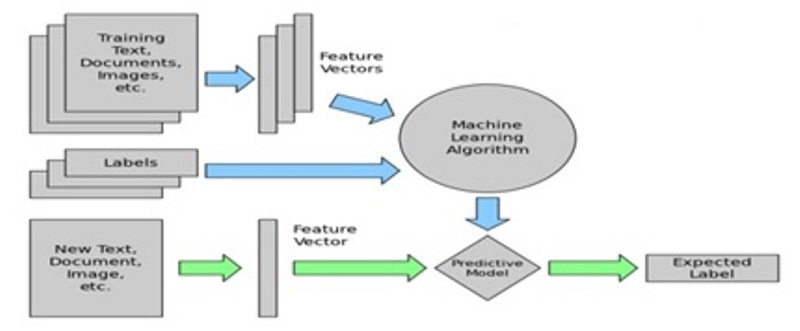
Basic Machine Learning Model for Text Classification
Various steps to b used in a machine learning-based text classification algorithm are as follows
(1)Features Extraction: This is a method used to transform the text into numerical representation in the form of a vector. One of the most frequently used approaches is a bag of words where a vector represents the frequency of words in a predefined dictionary of words.
For example, consider the following set of words
{This, is, the, not, excellent, bad, basketball}
Moreover, we suppose we have to vectorize the text “This is awesome” then, in this case, we would have the following vector representation of that text (1, 1, 0, 0, 1, 0, 0).
(2)Train the model: In the second step, machine learning algorithm is fed with training data that consist of pair of the featured set (Vector for each text example) and a tag to produce the classification model.
(3)Prediction: Prediction is the third step of the machine learning model. Once the model is trained with sufficient examples, the machine learning model begins to make an accurate prediction.
There are several approaches to creating ML models for various text-based applications, depending on what problem space and data is available.
Various Machine Learning Text Classification Algorithms
Some most popular machine learning algorithms used for text classification are Naïve Bayes algorithms, Support Vector Machine and deep learning.
Let us see each one by one.
(1)Naïve Bayes Machine Learning Algorithms
Naïve Bayes Learning algorithm is a statistical algorithm and can be used for text classification. Multinomial Naïve Bayes provide a good result when data is not available, and there is a lack of computational resources.
Naïve Bayes is based on Bayes’s theorem, and it helps us to compute the conditional probability of occurrence of each individual event.
This means that any vector that represents the text will have to contain the information about the probabilities of the appearance of the word of the text within the texts of a given category so that machine learning algorithms for text classification can compute the likelihood of the text belonging to the category.
(2)Support Vector Machine
Support vector machine is also a machine learning algorithm that is used for text classification. Support Vector Machine does not need so much training data to start providing an accurate result.
SVM takes more resources as compared to the Naïve Bayes algorithm. The main focus of SVM is to draw a line or hyperplane that divides a space into two subspaces. One subspace contains the vectors that belong to a group, and another subspace that does not contains the vector that does not belong to that group. These vectors are the representations of the training text, and a group is a tag.
(3)Deep Learning
Deep Learning is a subset of it, which is a refined version of the AI. Artificial Intelligence (AI), Is the capability of a machine to intimate intelligent human behaviour. AI’s bottlenecks are handled by Machine Learning (ML), which is handled by Deep learning.
Unlike AI and ML, Deep learning uses neural networks to simulate human-like decision making. Self-driving cars and voice-controlled assistance provided in the Phone are some of the examples of Deep learning using decisions from human behaviour. Deep learning-based machine learning algorithms for text classification are also used for this purpose.
Classic ML approaches like ‘Naive Bayes’ or ‘Support Vector Machines’ for spam filtering have been widely used for Preprocessing data.
Tokenization: turn sentences into words
Elimination of unnecessary punctuation marks
Elimination of stop words: frequent words like “The”, “is”, etc.
Regression
Simultaneously, parametric methods have been reviewed in machine learning algorithms for text classification; now, it is the turn to address this in the regression problem. Vector support machines follow the idea of finding a linear discriminate function that separates the classes.
As mentioned previously, the training set is a set of input-output pairs, i.e., where is the input and is the output. Assuming we have a binary problem and are represented by classes and, ie. So vector support machines try to find a function.
Natural Language Processing is a mix between Data Science, Machine Learning and Linguistics. Both in texts and in speech/voice. From analyzing syntactically or grammatically thousands of contents, automatically classifying into topics, chatbots and even generating poetry imitating Shakespeare.
It is also common to use it for Sentiment Analysis on social networks (for example, regarding a politician) and machine translation between languages. Assistants like Siri, Cortana and the possibility to ask and get answers, or even get movie tickets.
Mapping textual data to vectors with absolute values is called feature extraction. One of the most straightforward techniques for representing text numerically is Bag of Words.
Word Bag or Word Bag (BOW)
Creates a list of unique words in the body of text called a vocabulary. You can then represent each sentence or document as a vector. Each word is represented as one if the vocabulary exists and 0 if it does not.
The most common approach is to use the Document Inverse Frequency Term Technique (TF-IDF).
Time-frequency (TF) = (number of times the term t appears in the document) / (number of terms in the document)
Inverse Document Frequency (IDF) = log (N / n). N is the number of documents and n is the number of documents in which the term t appears. The IDF of rare words can be high, and the IDF of common words can see below. Therefore, it has the effect of highlighting different words.
Calculate TF-IDF values for terms such as = TF * IDF
Also, read this article to know more about text classification using machine learning.
Pretrained models for text classification
Please provide your feedback or leave a comment to improve and provide you with good quality tutorials.
If you find this machine learning algorithms for text classification tutorial helpful, then please Like and Share the post on Facebook, Twitter, Linkedin through their icons as given below.
