

Table of Contents
- 1 Decision Tree Algorithm in Machine Learning
- 1.1 Frequently Asked Questions
- 1.2 What is Classification in Machine Learning ?
- 1.3 Types of Classification Algorithms in Machine Learning
- 1.4 What is a Supervised or Unsupervised Model?
- 1.5 What is Decision Tree Algorithm?
- 1.6 Why is it Called a Decision Tree?
- 1.7 Terminologies related to Decision Tree Classifier
- 1.8 How to use a Decision Tree Classifier ?
- 1.9 Build the Tree with CART
- 1.10 Advantages of Decision Tree
- 1.11 Implementation of Decision Tree Algorithm in Python
- 1.12 Conclusion and Summary
Decision Tree Algorithm in Machine Learning
Decision tree algorithm in machine learning is widely used in different application. Now a days Machine Learning is an emerging area to learn for a computer science engineering student. Lot of Jobs are coming in the market of software industry.
Lot of Computer Science Engineering Students are doing training in Machine Learning for making prosper career or Job in Machine Learning Field.
Today in this Tutorial we will discuss every aspects of Decision Tree Algorithm. Students are kindly requested to read this tutorial till the end. In the last portion we have also cover the implementation of decision tree algorithm in python with codes and output.
Decision Tree Algorithm is an important of Classification Algorithms in Machine Learning. Classification Algorithm is the type of Supervised Learning.
We encounter several applications of Machine Learning daily if we look around. From Gmail’s Spam Detection to Facebook’s Face Detection technique everything is related to Machine Learning. Machine Learning is the process of training the machine to learn the behavior of data to act fast and efficiently.
Frequently Asked Questions
By the end of this tutorial students will be able to answer the following questions in context about Decision Tree.
- What is Decision Tree ?
- What are Classification Algorithms ?
- What are different types of classifications algorithms ?
- What are terminology related to digital classifier?
- How to use a Decision Tree Qualifier ?
- How to build tree using CART ?
- What are advantages of decision tree?
- How to implement implement decision tree in Python ?
- Is decision tree is a Greedy Algorithm ?
- In which algorithm data in tree always occur in leaves ?
- Why the search path in a state space tree of a branch and bound algorithm is terminated?
- How do we create a decision tree ?
What is Classification in Machine Learning ?
Classification is a way of categorizing the observations or datasets into different categories by adding labels to them. In classification we take the data, analyze it and on the basis of some conditions we divide it into different categories.
Why do we Classify the Data?
To perform Predictive Analysis on the data we classify the data. For example, when we receive a mail, Gmail will classify it on the basis of its past data and will predict whether it is a spam or a promotion or an important mail.
In this case, the machine will predict that something fishy may be going around here and sends a notification to confirm whether the log in was done by the account holder or someone else.

Types of Classification Algorithms in Machine Learning
There are several types of classification algorithms used in machine learning. These techniques are used to train the machine. Some of the widely used machine learning algorithms are as follow –
- Decision Tree.
- Random Forest Classifier.
- K- Nearest Neighbor classifier.
- Naive Bayes.
- Logistic Regression.
- Linear regression.
- Support Vector Machine.
Here we are going to discuss about decision tree algorithm in detail.
Since decision tree algorithm is a type of Supervised Learning. So let’s first understand what is supervised learning ?
What is a Supervised or Unsupervised Model?
- Supervised model: In this learning technique the machine learning model is trained on a labeled dataset so that it can predict the outcome of out-of-sample data.
- Unsupervised model: Unsupervised learning uses machine learning algorithms that draw conclusions on unlabeled data. They have more difficult algorithms than supervised learning as we know little about the data or the outcomes to be expected.
Key Point – Decision tree algorithm is a supervised learning technique as it uses labeled datasets to predict the outcomes.
What is Decision Tree Algorithm?
Decision Tree may be defined as the graphical representation of all the possible solutions to a decision. The decisions are based on some conditions. We have explained decision tree example with solution.
Let’s take a very simple example. You want to watch a tv show and based on its timings you need to predict whether you’ll be able to watch it or not. The simple steps followed would be-
The above diagram is a simple example of decision tree based on some simple conditions.
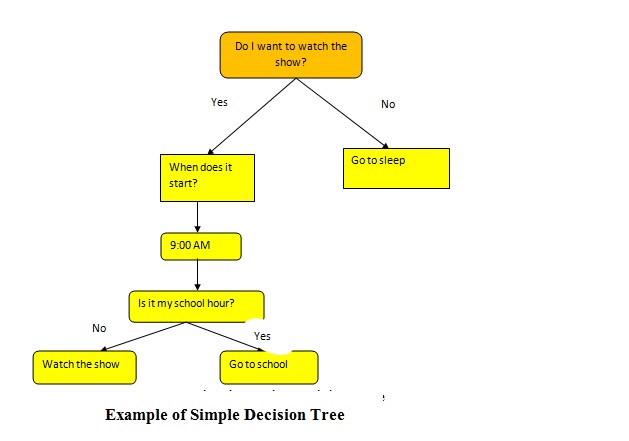
Why is it Called a Decision Tree?
Decision Tree is really very easy to read and understand. It is a model which is easily interpretable and you can understand exactly why the classifier has made the particular decision.
It is called a decision tree because it starts with a root and then creates branches to a number of solutions just like a tree and the number of branches increases with the increasing number of decisions or conditions. A tree grows from its roots and then creates branches as it gets bigger and bigger.
This concept of Decision Tree Algorithm can be explained with the following diagram:
Here you are trying to decide whether you want to accept a new job offer or not.
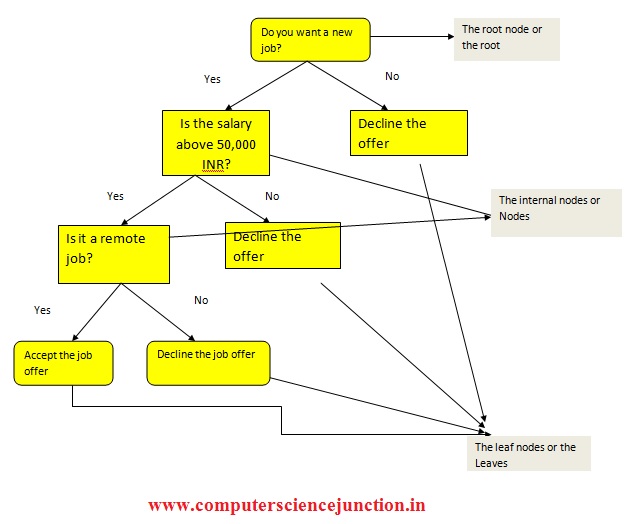
The internal nodes have arrows pointing to them or they have arrows pointing away from them. Leaf nodes have arrows pointing to them but there are no arrows pointing away from them.
- Root node: Root node is the point where the decision tree starts.
- Leaf node: These are the final output nodes of the decision tree.
- Splitting: Splitting is the process of dividing the sub nodes or internal nodes on the basis of conditions provided.
- Pruning: It is the process of removing unwanted branches from the tree.
- Parent/ Child node: The root node is called the parent node and all the other nodes are called the child nodes.
How to use a Decision Tree Classifier ?
In order to build a tree on the basis of a dataset we will use a decision tree algorithm called CART which stands for Classification and Regression Tree Algorithm.
At first let’s focus on the steps
- We begin the tree with the root node as shown in above figure and the root node receives the entire dataset.
- Then we find the best attribute in the dataset by using ASM Attribute Selection Method technique.
- Divide the root node into some subsets which will contain the best possible values for the best attribute.
- Then we generate the decision tree node from the best possible attribute.
- We recursively make new decision trees using the same dataset and continue this process till a stage is reached after which we can’t classify it further. The final nodes are called a leaf node.
Build the Tree with CART
First we need to find the best attribute and where to split the tree. To split the tree we need to know some terminologies.
- Gini Index: It gives the measure of impurity or purity of the dataset used in the CART algorithm. An attribute with low Gini index is preferred over high Gini index.
We can calculate Gini index by using the following equation
Gini Index= 1- ∑jPj2
2. Information Gain: After the dataset is split based on an attribute, the decrease in entropy is called the information gain. The attribute having the highest information gain is selected.
Entropy is the measure of impurity in a given attribute. Impurity of a data is the degree of randomness of the data.
Advantages of Decision Tree
Several advantages of decision tree algorithm are given below
- Fewer amounts of data cleaning is required compared to other techniques.
- It is very useful in solving decision related problems.
- It is way too easy to understand and interpret even for the learners.
Implementation of Decision Tree Algorithm in Python
Python is a very advanced an easy programming language. Let’s implement the decision tree algorithm with Python and check the results.
Python is a very useful tool for Statistical Analysis. We will implement decision tree algorithm with Python. Following steps are need to follow to implement the decision tree algorithm.
Software or Platform Required
- First We need to install Anaconda distribution Successfully.
- Once the Anaconda is installed successfully then in Anaconda distribution Jupyter Notebook is already available, that is a platform to create and share documents which contains visualizations, live coding etc. We will use Jupyter Notebook for writing the code.
- Insert the codes on the cells and to run the code press ‘shift+enter’.
- Insert each of the codes in each cell and run the cell to get the output.
- The file will be automatically saved.
Decision Tree Machine Learning Example – Problem Statement
In this section we are going to explain decision tree machine learning example. Let’s us understand this example.
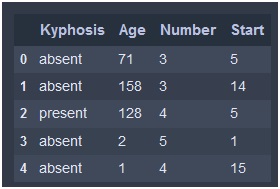
Here in this example , we are taking a ‘Kyphosis.csv’ file to implement decision tree classifier. Here we need to predict whether Kyphosis is present or absent on the person or not. The dataset looks like the following image.
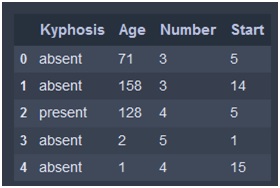
Solution
To solve the above problem it means to predict the Present or Absent in csv file we will use decision tree algorithm and implement in python
The necessary steps to implement decision tree algorithm are as follows
Step1– Data Pre-processing
#importing the required libraries
- import pandas as pd # to read the data
- import numpy as np
- import matplotlib.pyplot as plt # data visualization
- import seaborn as sns # data visualization
# get the data
- df = pd.read_csv(‘kyphosis.csv’)
- df.head()
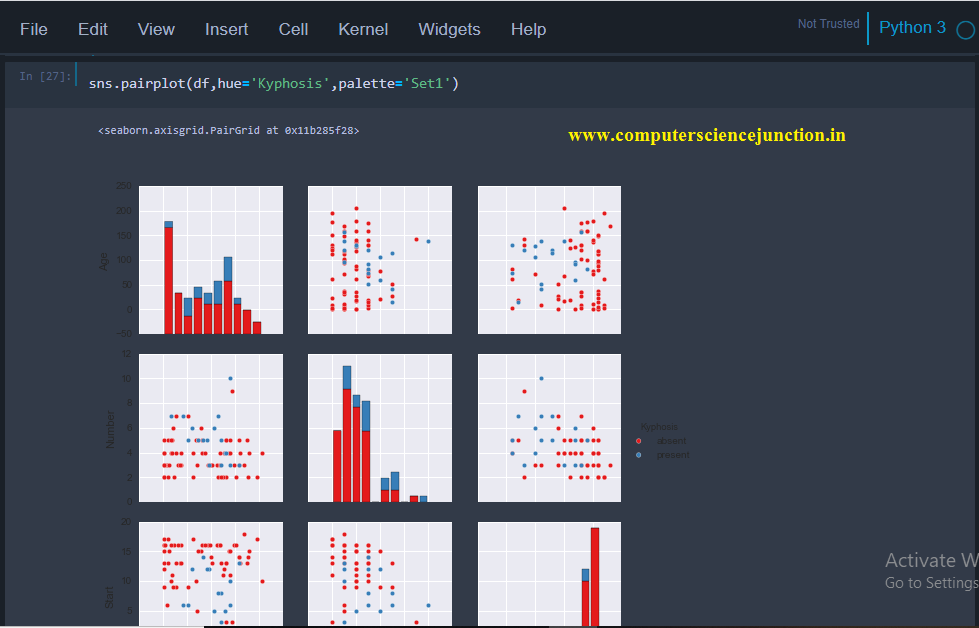
# data visualization
sns.pairplot(df,hue=’Kyphosis’,palette=’Set1′)
# splitting the data into train and test data
- from sklearn.model_selection import train_test_split
- X = df.drop(‘Kyphosis’,axis=1) # train data
- y = df[‘Kyphosis’] # test data
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30) # split the data into train and test data
Snapshot for Jupyter Notebook for the above code and output is as shown in following picture.
Output of get date is as shown in following picture
Output of Data Visualization for above code is as shown in the given below
Output for Splitting the data in train and test model is as shown in following picture
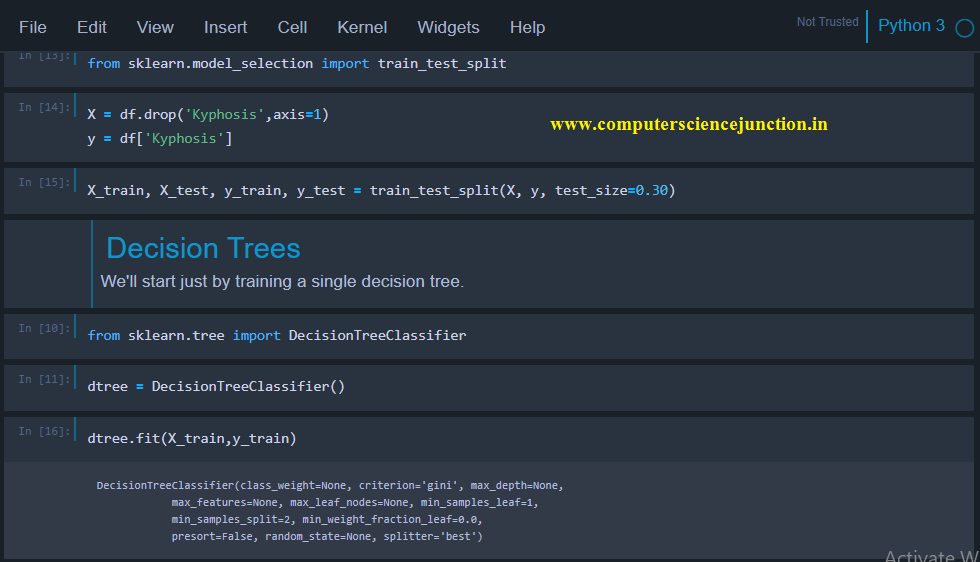
Step 2 – Fitting a decision tree classifier to the training set
- from sklearn.tree import DecisionTreeClassifier
- dtree=DecisionTreeClassifier()
- dtree.fit(X_train,y_train)
Output of Step 2 is as shown in following figure and full snapshot is shown in above figure.
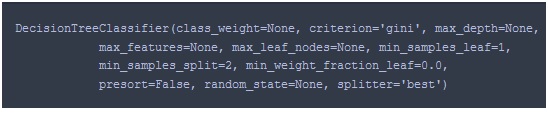
Here criterion=’gini’
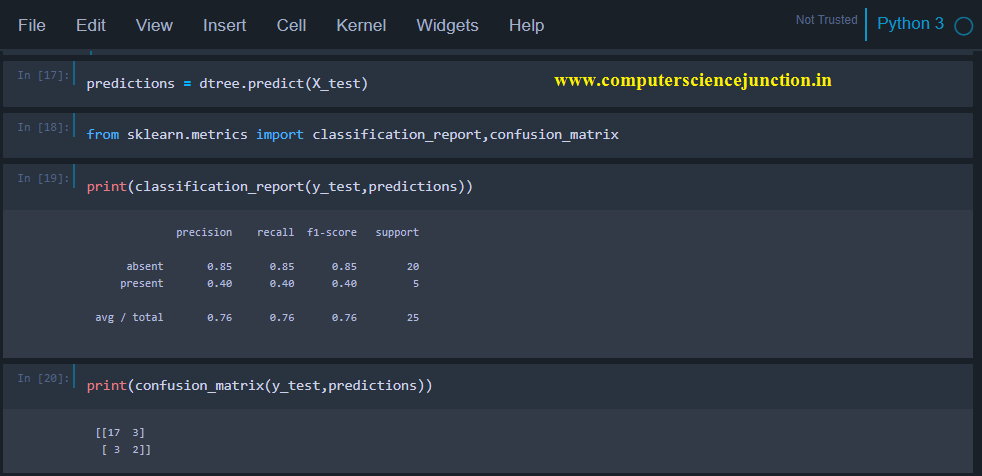
Step 3 – Prediction and evaluation
- predictions = dtree.predict(X_test)
- from sklearn.metrics import classification_report,confusion_matrix
- print(classification_report(y_test,predictions))
print(confusion_matrix(y_test,predictions)) # confusion matrix shows the performance of a classifier.
Output and code snapshot for prediction and evaluation model including confusion matrix is as shown in following picture.
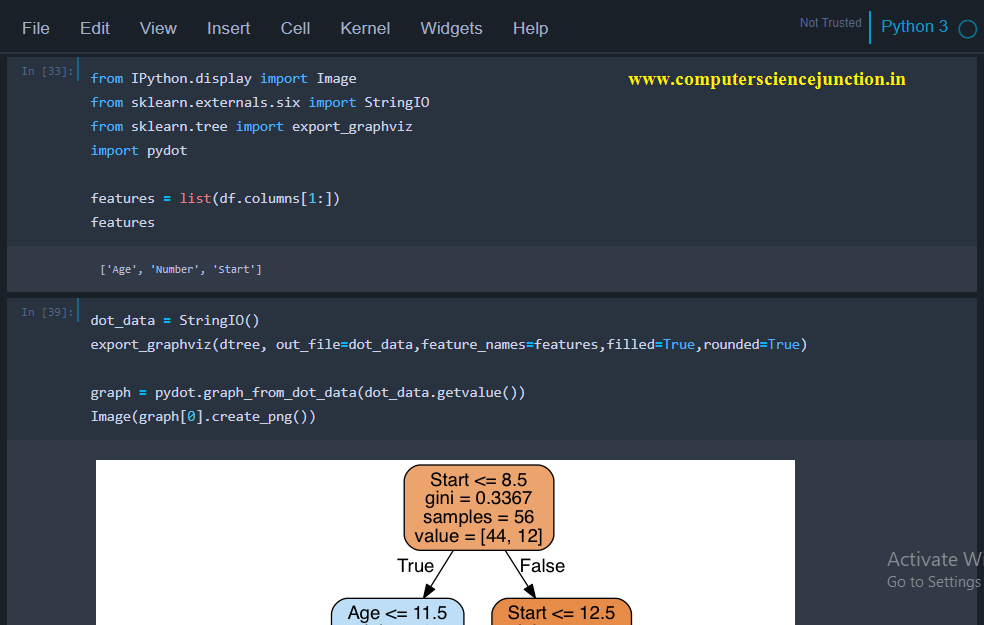
Step 4 – Tree Visualization
- from IPython.display import Image
- from sklearn.externals.six import StringIO
- from sklearn.tree import export_graphviz
- import pydot
- features = list(df.columns[1:]) # contains the train data features
- dot_data = StringIO()
- export_graphviz(dtree, out_file=dot_data,feature_names=features,filled=True,rounded=True)
- graph = pydot.graph_from_dot_data(dot_data.getvalue()) # creating the image of the tree
- Image(graph[0].create_png())
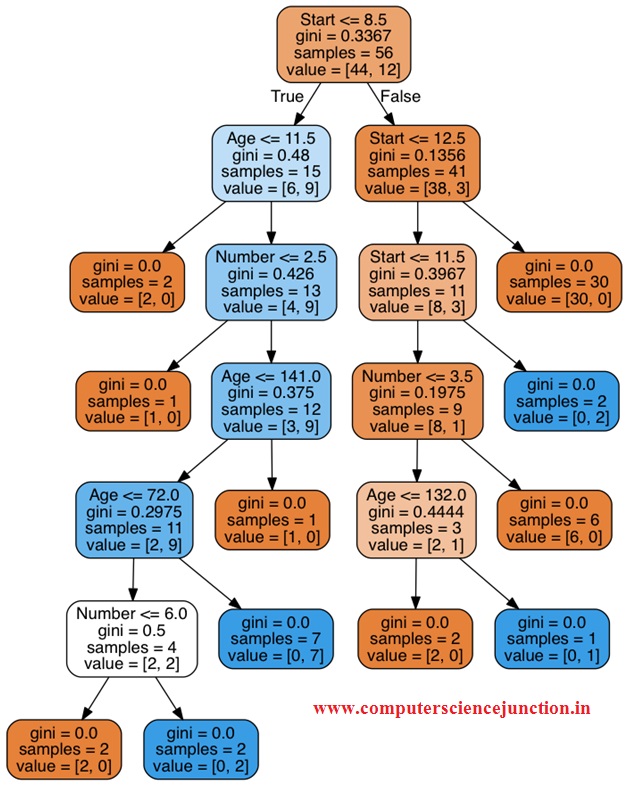
The tree as shown in above figure is the final decision tree for the example considered in this tutorial.
Snapshot for above code and output is as shown in following picture.
Conclusion and Summary
In this Decision Tree Algorithm in Machine Learning tutorial we have explained various aspects of decision tree such as decision tree machine learning example and decision tree algorithm implementation in python. We have also learned about the classification
algorithms in machine learning. We have also learned about the advantage of decision tree algorithm.
I hope that this tutorial will be beneficial for the computer students.
I kindly request to readers please give your feedback and suggestion. If you find any mistake in this tutorial then comment.
If you want to add or contribute some more information to this tutorial then mail us at the email id computersciencejunction@gmail.com
Don’t stop learning and practice.
All the Best !!
